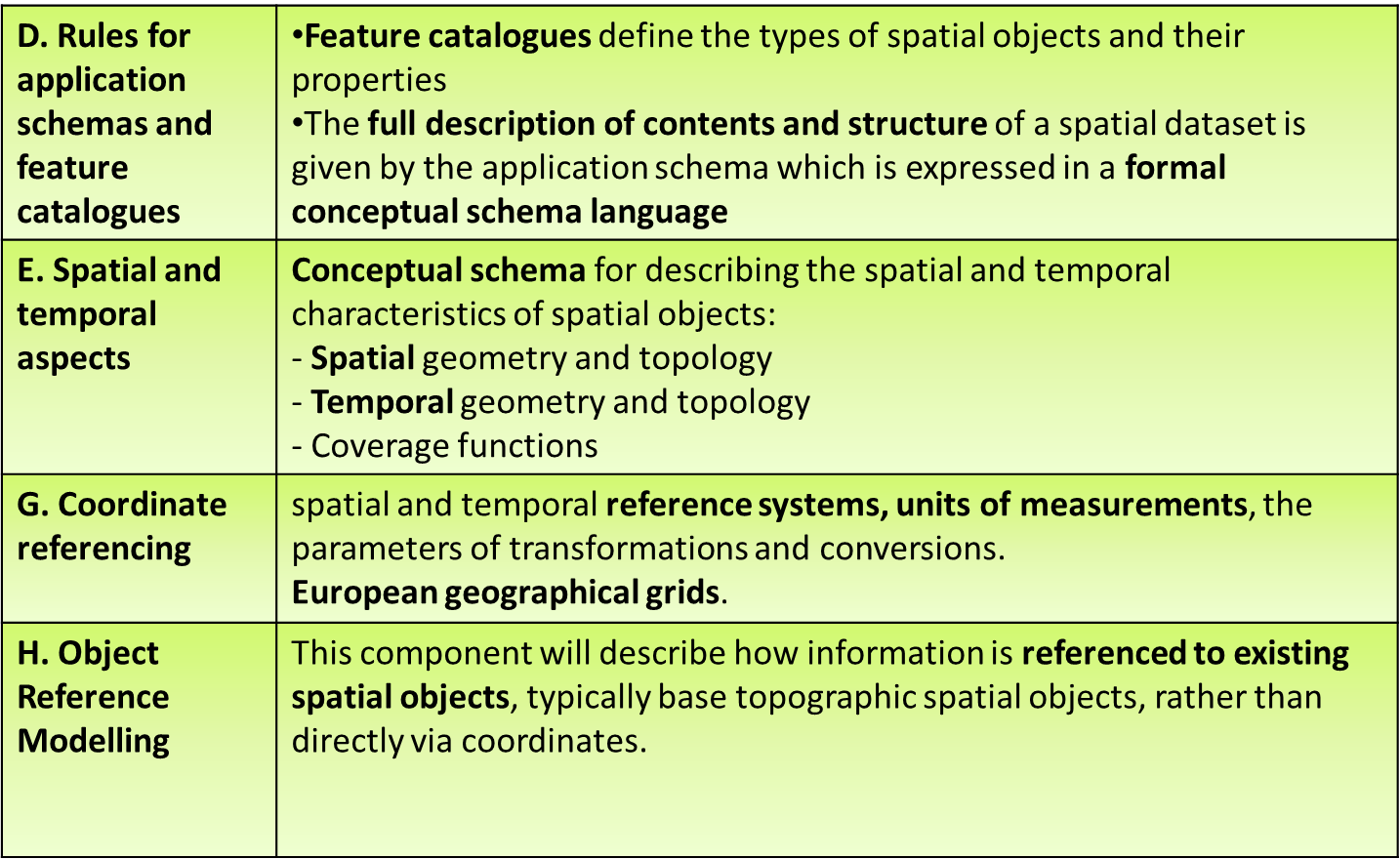
Data models and data specifications Use of models, scope and specification objectives. Modelling frameworks and applied examples
WELCOME!
With the following slides and interactive material you will be able to take part in the journey to discover Spatial Data Infrastructures SDI ) its components and benefits through the observation of multiple examples and exercises.
You can navigate through the course by pressing the navigation arrows at the bottom of each slide or using your arrow keys on your keyboard. You can move horizontally ( ← →) (↑↓)
MetadataData models and data specifications
# Contents 1 Motivation and Background 2 Scope & objectives of data specifications for SDI’s 3 The modelling framework for data specifications (ISO 19131) 4 Development of data specifications 5 Examples of data models: ISO 19152
Interoperability of data
Motivation and Background
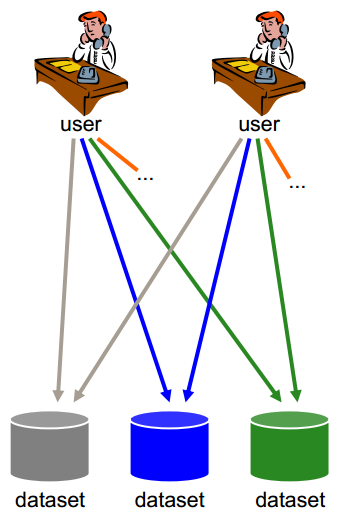
Access to spatial data in various ways: copies via CD
User has to deal with interpreting heterogeneous data in different formats, identify, extract and post-process the data needed
→ Lack of interoperability
Notes for slide 4
This slide shows the situation when there is no interoperability at all, this reflects how it used to be.
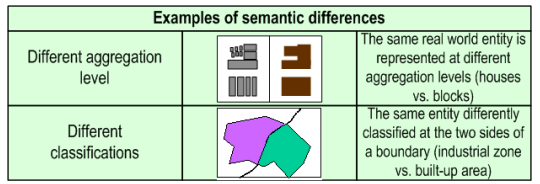
Examples of incompatibility and inconsistency of spatial data
Semantic and schematic differences
Semantic and schematic differences
Notes for slide 5
This slide addresses some issues of incompatibility and inconsistency which can happen at the borders (in different MS).
Levels of heterogeneity (1)
Syntactic heterogeneity
Data may be implemented in a different syntax of different paradigms, such as relational or object- oriented models. Syntactic heterogeneity is also related to the geometric representation of geographic objects, e.g., raster and vector representations.
Structural or schematic heterogeneity
Objects in one database are considered as properties in another, or object classes can have different aggregation or generalisation hierarchies, although they might describe the same Real World concepts.
Notes for slide 6
We just talked about the lack of interoperability in different data sources.
Levels of heterogeneity (2)
Semantic heterogeneity
A Real World concept may have more than one meaning to comply with various disciplines, giving as a consequence semantic heterogeneity.
e.g. Different classifications/definitions of roads when viewed from different perspectives: traffic network route directions, spatial planning… <> 1 on 1 match
Notes for slide 7
The 3rd level of heterogeneity is the semantic heterogeneity.
Interoperability of data (1)
Technical interoperability
should guarantee that system components can interoperate
Semantic interoperability
should guarantee that data content is understood by all in the same way
Notes for slide 8
The scope now is to make data interoperable and to solve the different levels of heterogeneity that we talked about in the previous slides. The result would be that each producer and each user can easily exchange data amongst each other with our without the aid of a coordinator in between.
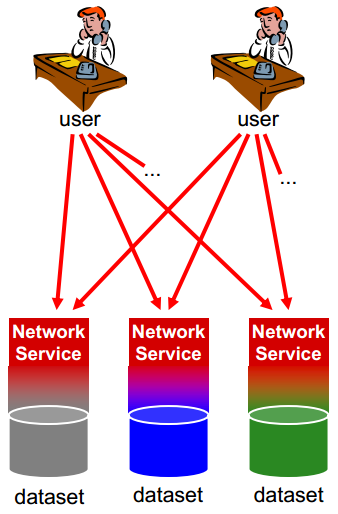
Interoperability of data (2)
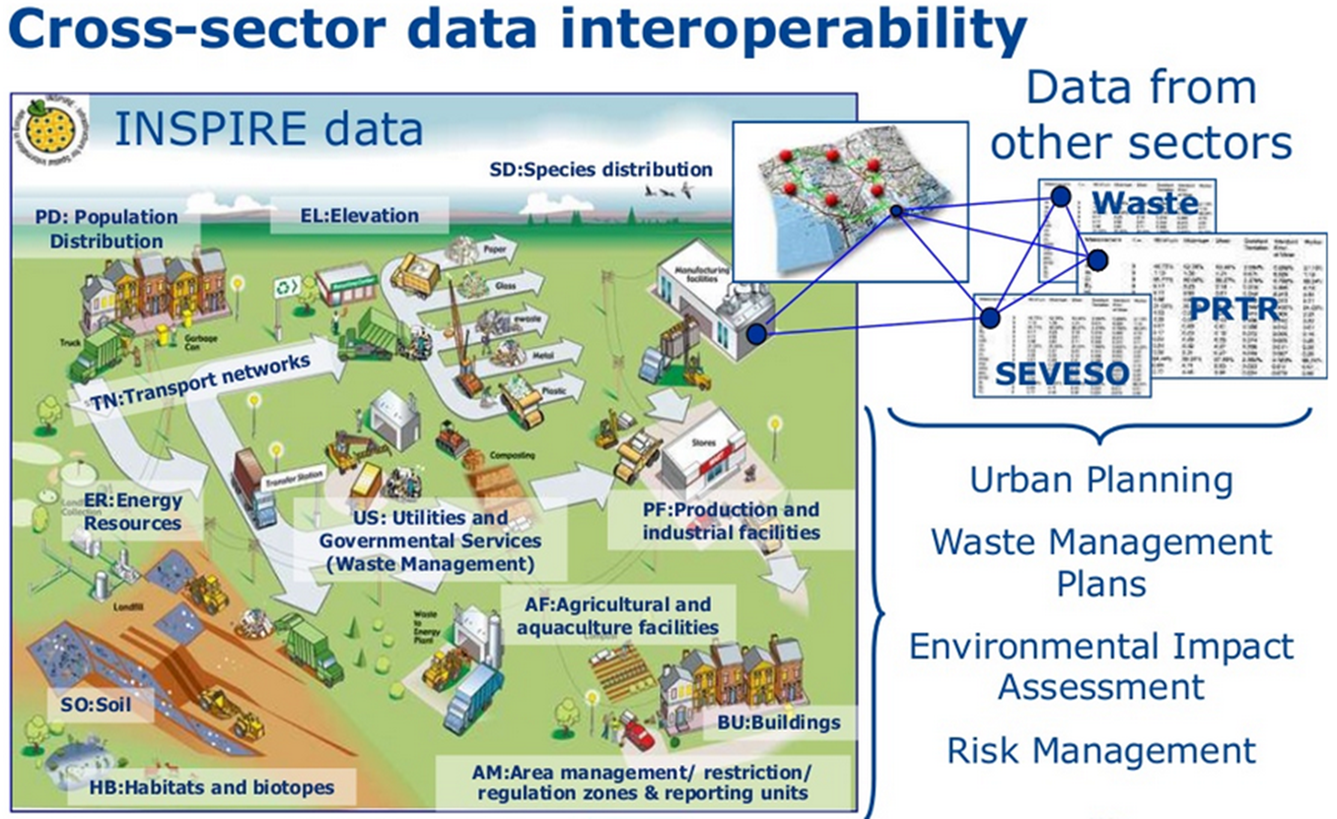
Provide access to spatial data via network services and according to a harmonised data specification to achieve interoperability of data
Datasets used within organizations may remain unchanged
Data or service providers have to provide a transformation between their internal model and the harmonised data specification
Notes for slide 9
This slide shows in a graphical way what INSPIRE is aiming at:
How?
Facilitate data use and interoperability by adopting common cross-domain models to exchange data
DATA INTEROPERABILITY
Notes for slide 10
How can we make this facilitation of data access, data use and interoperability work. It is through defining common cross-domain models that will be used to exchange the data. You can compare it with selecting the right plug that fits the socket.
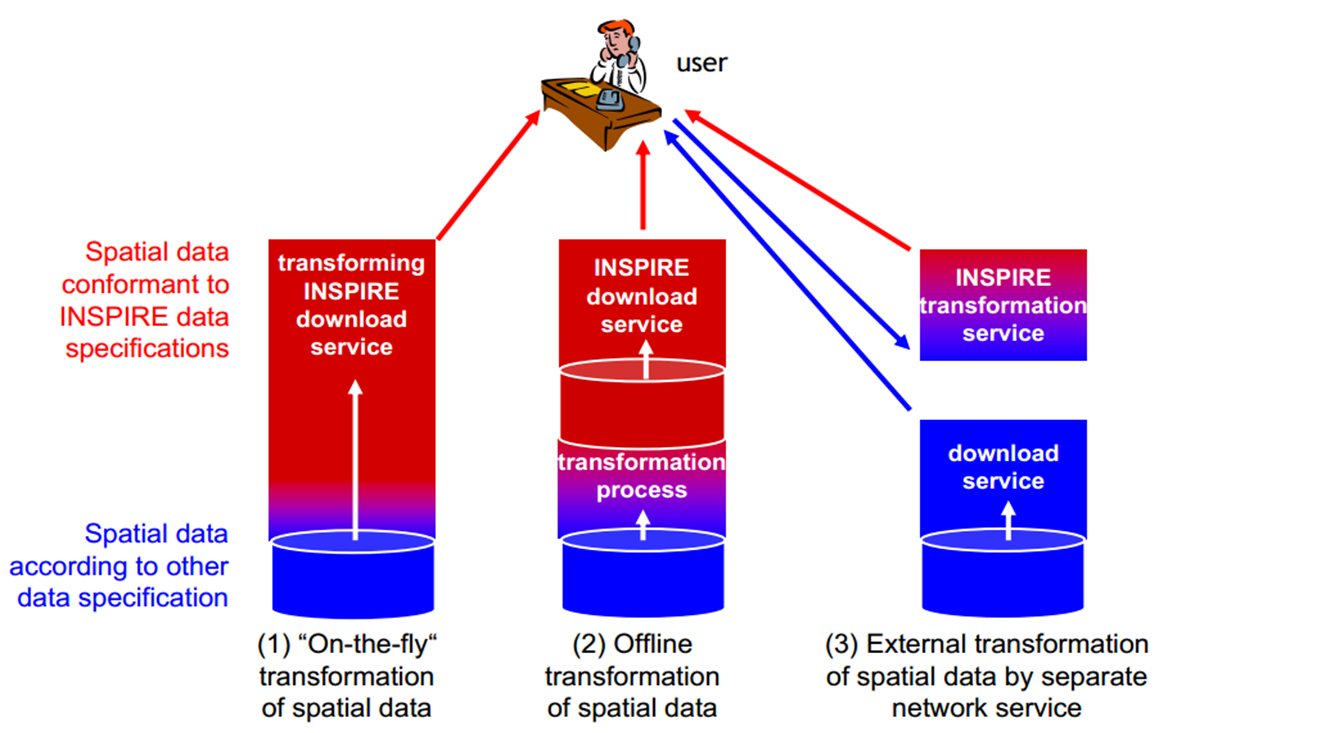
Implementation alternatives
Notes for slide 11
What are now the different implementation alternatives to reach this harmonisation towards the INSPIRE DS? At the start of the INSPIRE story, three different implementation strategies were proposed:
Conclusion: common Data Specifications is the goal
Member States should make data available within the scope of INSPIRE using
the same spatial object types (and definitions)
the same attributes (and definitions, types, code lists) and relationships to other types, e.g. BuildingHeight, BuildingSize
a common encoding (GML application schemas)
common portrayal rules
This facilitates interoperability and pan-European/cross-border applications (e.g. information systems, reporting systems, forecasting models)
Notes for slide 12
The common data specification goal can be resumed as follows:
Targeted benefit
Source: EC Joint Research Centre
Notes for slide 13
Picture of the ideal world as we would like to have it.
Example: key requirements of the INSPIRE directive (1)
Art 3(7): “Interoperability means the possibility for spatial data sets to be combined , and for services to interact, without repetitive manual intervention , in such a way that the result is coherent and the added value of the data sets and services is enhanced”
Art 7(1): “Implementing rules laying down technical arrangements for the interoperability and, where practicable, harmonisation of spatial data sets and services … shall be adopted…. Relevant user requirements, existing initiatives and international standards for the harmonisation of spatial data sets, as well as feasibility and cost-benefit considerations shall be taken into account in the development of the implementing rules.”
Notes for slide 14
Without repetitive manual intervention: no need for preprocessing anymore
Example: key requirements of the INSPIRE directive (2)
implementing rules shall address the following aspects of spatial data:
(a) a common framework for the unique identification of spatial objects , to which identifiers under national systems can be mapped in order to ensure interoperability between them;
(b) the relationship between spatial objects;
(c) the key attributes and the corresponding multilingual thesauri commonly required for policies which may have an impact on the environment;
(d) information on the temporal dimension of the data;
(e) updates of the data.
Notes for slide 15
In article 8 we see that these implementing rules will address a certain number of aspects of spatial data:
02 | Scope & objectives of data specifications for SDI’s
Thematic scope
Notes for slide 17
In general we can say that INSPIRE is aiming at thematic domains that concern environmental policies - public sector data. This slide shows the complete list of thematic domains (34 in total) which are grouped in 3 annexes because of different priorities, different timeline and deadlines to implement data components of the INSPIRE directive.
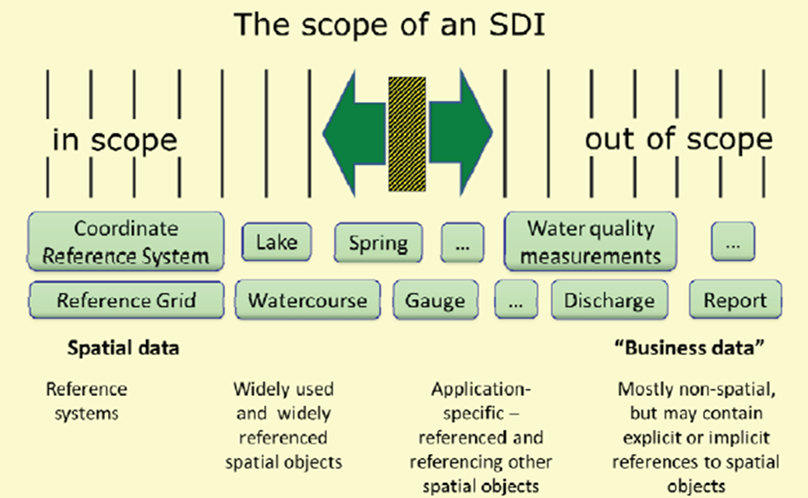
SDI data scope
Scope is spatial data – not all kinds of thematic/descriptive data
Re-use the INSPIRE data specs for own usage
Extensions
Additional constraints
Re-use of common objects
Notes for slide 18
Although we tend to attach a lot of thematic data to the spatial data, this is not the scope of INSPIRE.
Exercise 1: Find your scope
Go to INSPIRE website https://inspire.ec.europa.eu/inspire-tools
Use the tool “Find your scope” (toolkit):
In catalogue of INSPIRE objects:
find “zone” --> limit to only “Spatial object type” --> narrow search “terrestrial zone”
Which Object, INSPIRE Data Theme, Application Schema
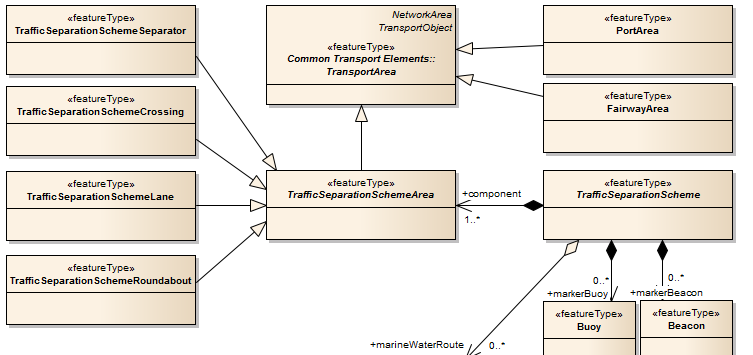
What are the other possible specialisations of TransportArea?
To find the Spatial object that should be used for a dataset that stores the locations of stations where magnetic measurements are performed. (use “Direct Search”)
Find your own scope…
1
Exercise 1: Result (1)
PortArea – Transport Networks – Water TN
Exercise 1: Result (2)
Direct search: “magnetic field”
Relevant objects? Observed Event (NZ) vs Geoph Station (GE - Geophysics)
03 | The modelling framework for data specifications (ISO 19131)
Data harmonisation and data specs aspects
Notes for slide 24
We already saw that the GCM is the guidance for good modelling practises for all DS. The result of the modelling should be a harmonised set of DS for all themes.
Harmonisation General Principles
Notes for slide 25
We can distinguish some categories in the list of harmonisation aspects. First of all there are some “General principles”:
Harmonisation Schemas
Notes for slide 26
Beside the general principles we also have some principles related to schemas:
Harmonisation Translations
Notes for slide 27
The following slide brings us to the category of translation aspects.
Harmonisation Identification
Notes for slide 28
Next category of harmonisation aspects is concerning the identification of objects.
Harmonisation Data Quality
Notes for slide 29
A last category of harmonisation aspects concerns “data quality” elements.
Harmonisation Other aspects
Notes for slide 30
All aspects on this slide do not fit in one of the previous categories however they cannot be disregarded when it concerns data harmonisation.
Some wrap-up questions
The modelling framework
Where does the abbreviation GCM stands for (used in the INSPIRE context)?
How many thematic domains, divided in how many annexes, are addressed by the INSPIRE directive?
Which kind of heterogeneity?
What are next from “Encoding” and “Harmonised vocabularies” the other two major cornerstones of data interoperability?
04 | Development of data specifications
Let’s have a quick look now to the development process of the DS in part 3 of this module.
What is a data specification?
DATA SPECIFICATION
II
Synonym to data product specification
Detailed description of a data set or data set series together with additional information that will enable it to be created, supplied to and used by another party
[ISO 19131]
Notes for slide 33
We already talked a lot about DS:
Data Specification
Notes for slide 34
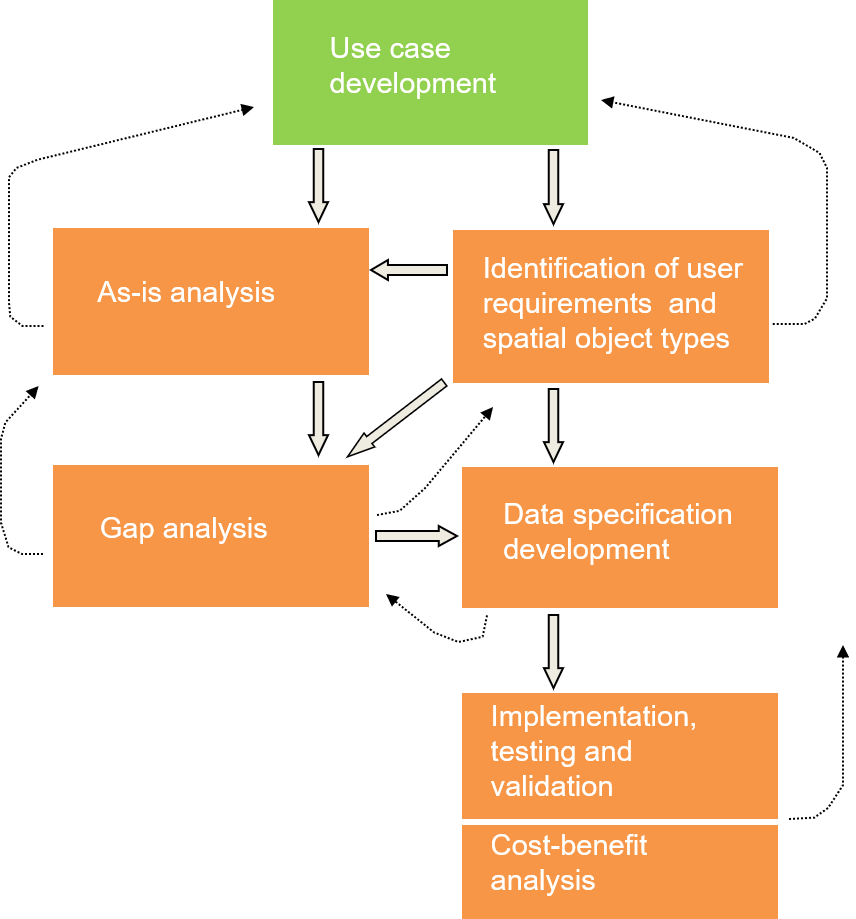
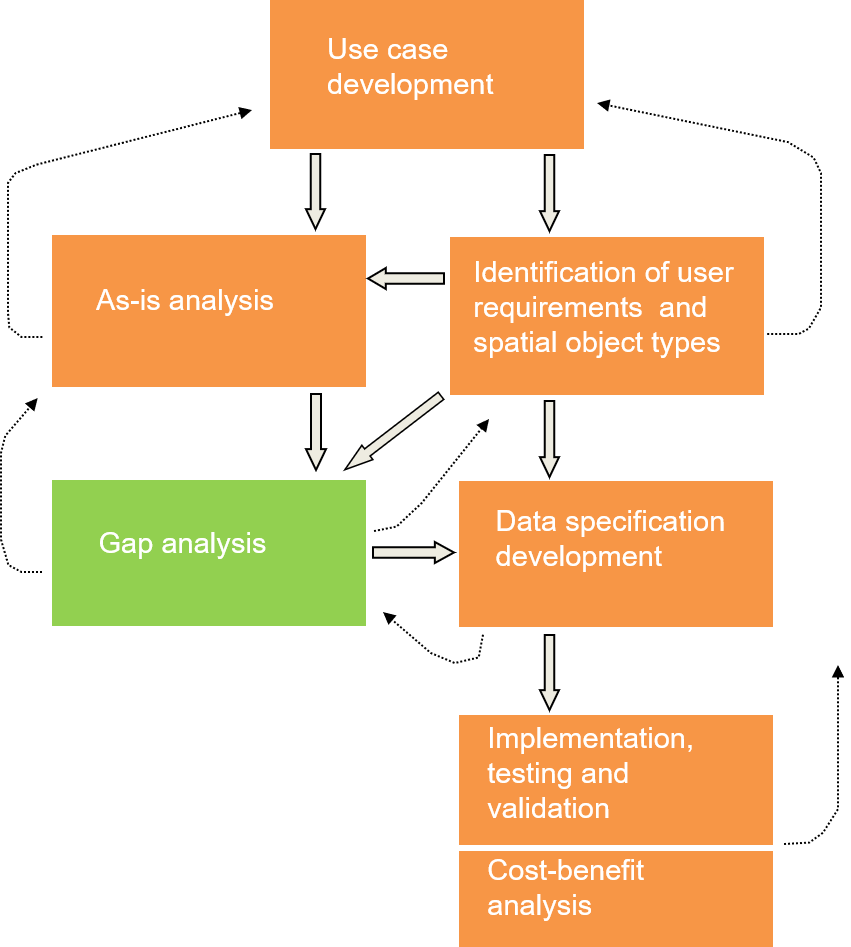
The creation process of such INSPIRE DS followed a step-wise methodology with moments of feedback and with the involvement of the relevant stakeholders. Here on this slide you can see the workflow of the process indicating as well the feedback possibilities (iterations) between the different steps.
Use case development
Step 1
Major sources are:
European environmental policies
User requirements survey
SDIC/LMO reference material
EU-funded initiatives and projects
Notes for slide 35
The first step in the development process was the defining of relevant use cases.
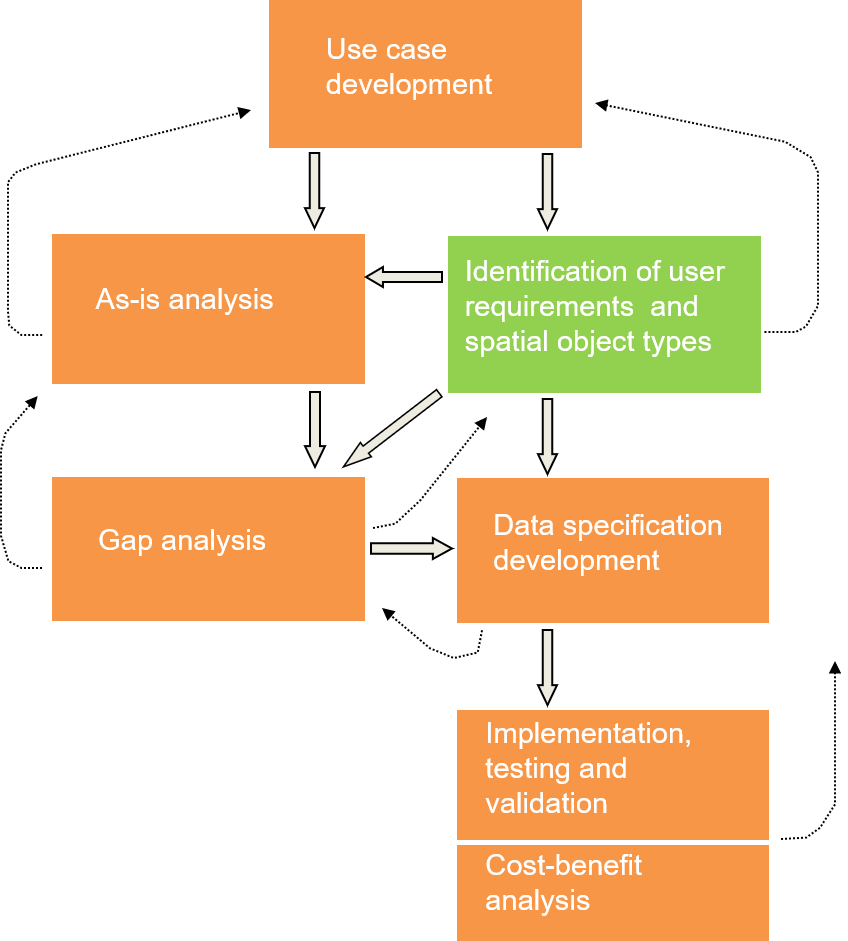
Identification of user requirements and spatial object types
Step 2
Identify requirements on:
the data content
metadata, data quality, portrayal and other elements of the data specification
Notes for slide 36
The second step was, to identify the User Requirements and the essential spatial objects from all the material gathered in the first step.
As-is analysis
Step 3
Analyse the current situation regarding spatial data sets for the theme, based on:
Notes for slide 37
In the third step is based on the reference material provided in the first step. It concerns an As-Is analysis of the current situation regarding current procedures and workflows of (theme specific) spatial data sets.
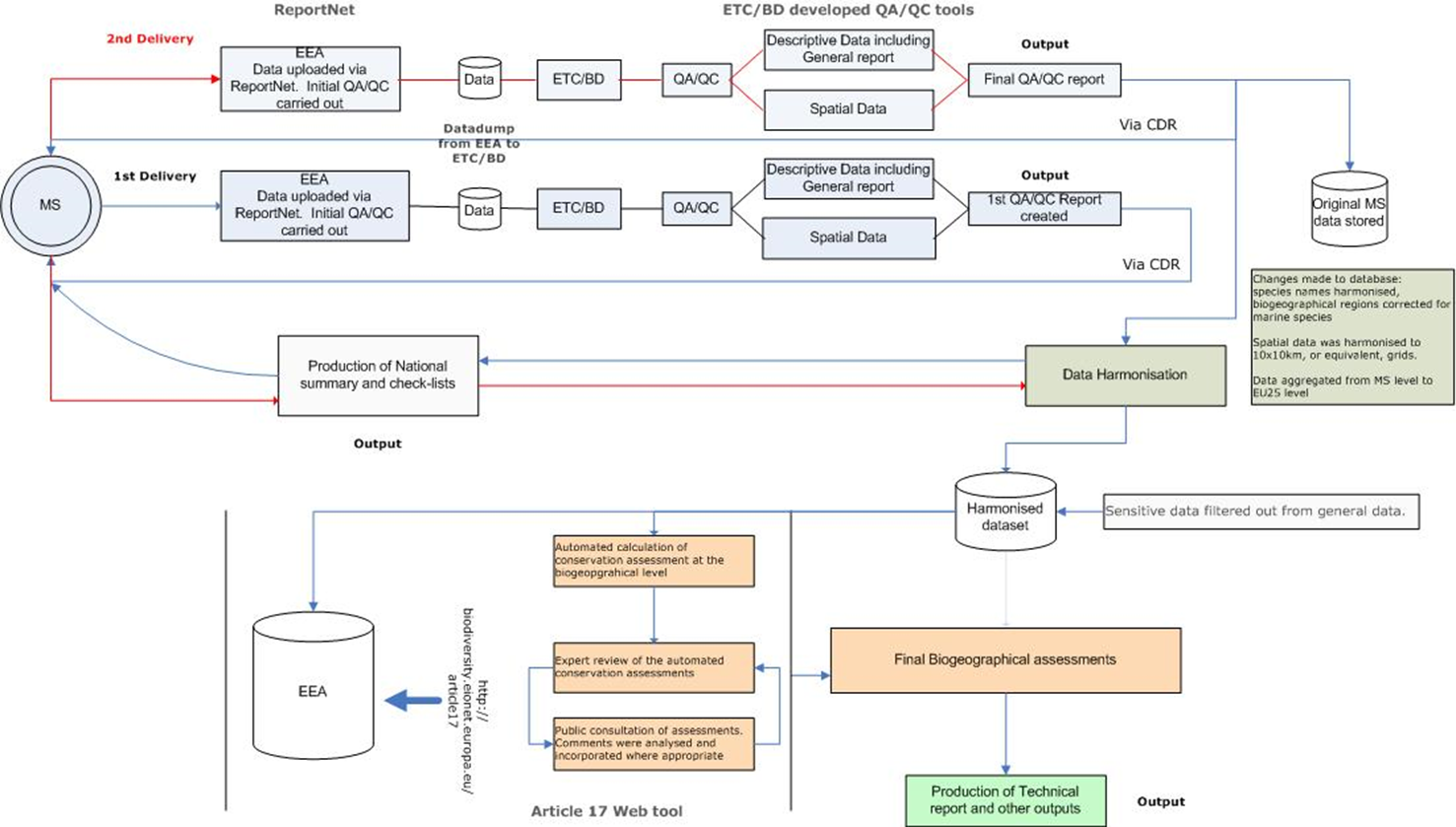
Example of As-is analysis
Notes for slide 38
This slides gives an example of the workflow that MSs should follow, to report on Habitats according a certain article of the Habitat directive. The MSs need to report on and upload data to the EEA and ETC/BD, they perform a QC, based on the result a second delivery with corrections can be asked. The final result is then stored in a common repository from which a harmonised database on the state of habitats throughout Europe is created. This resulting database can then be used by the EEA to make new assessments according the Biogeographical Regions of Europe.
Gap analysis
Step 4
Compare identified data sources with identified user requirements
Notes for slide 39
In the fourth step the user requirements are compared to what is already present in existing data sources. User requirements that are not met yet are identified as “Gaps”. This is called the gap analysis phase. DS must be designed to close these gaps.
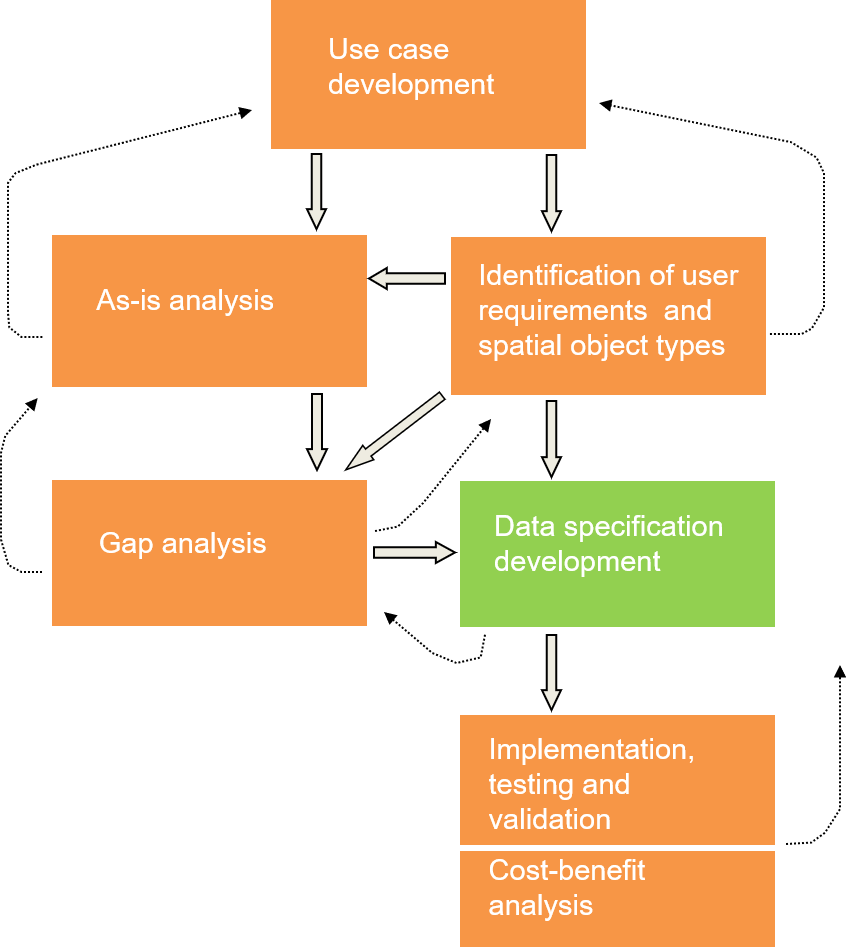
Data specification development
Step 5
The data specifications must be designed to ensure easy mapping between existing data and the harmonised data specification.
Consider:
Notes for slide 40
All previous steps belong to the preparation phase for the real development of the DS. The development of the DS was done by a group of domain experts (TWG). That group had to design the DS in such way that the user requirements were met and that the mapping between the existing data and the final harmonised model was quite straight forward.
Implementation, validation and Cost-Benefit Analysis
Step 6-7
review process
test under real world conditions
analyse costs and benefits
Final round of harmonisation
Notes for slide 41
The resulting draft versions of the DS were then implemented and send back to the data communities for testing and validation in real world conditions.
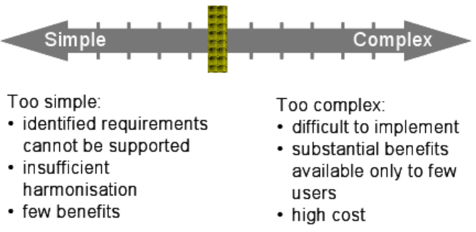
Which level of harmonisation is “just right”?
Notes for slide 42
When developing DS it is important to find the appropriate level of harmonisation.
Result
Data specification for all Annex Themes
Notes for slide 43
To resume and also to make the link to the next part of the module ‘understanding the technical guidelines’, I give you again the result of the DS process.
05 | Examples of data models: ISO 19152
In the following slides I will try to guide you through the DS document of CP which is an annex I theme. I’ll just highlight some elements that are really theme specific by following the DS document structure.
CP - Scope
The scope of the cadastral information in the INSPIRE context is limited to the geographic side of the cadastral information systems (land administration) INSPIRE does not aim at harmonising the concepts of ownership and rights related to the parcels Cadastral parcels should serve the purpose of generic information locators. Having included the reference to the national registers as a property (attribute) of the INSPIRE parcels, national data sources can be reached. If you look at the scope of CP as listed in the DS document you can see that in the INSPIRE context cadastral information is limited to the geographic side of the cadastral information systems (managed by a land administration). So all business information related to the geographic component is out of scope and should not be made available throughout INSPIRE.
CP - Bacground
All countries run a register Usually a partition of the country with exceptions Basic unit of the system is the parcel The cadastral parcels should be, as much as possible, single areas of Earth surface (land and/or water) under homogenous real property rights and unique ownership, where real property rights and ownership are defined by national laws. By looking at the background documentation of the CP DS, you will see that:
CP - Basic components
Parcel (basic unit) Subdivision (municipalities, sections, districts, parishes, urban or rural blocks, etc) Carry information for the parcels inside the subdivision: accuracy or scale Cadastral boundaries Only neccessary if spatial accuracy is associated with them By taking into account this background information we can better understand how the basic components of the CP data model were chosen.
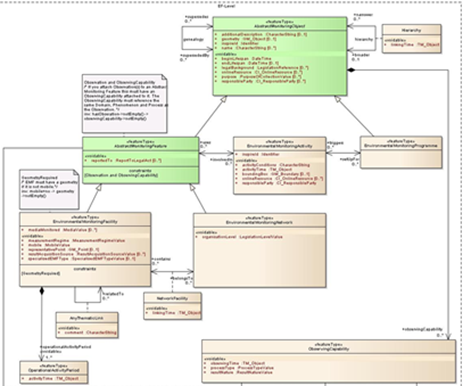
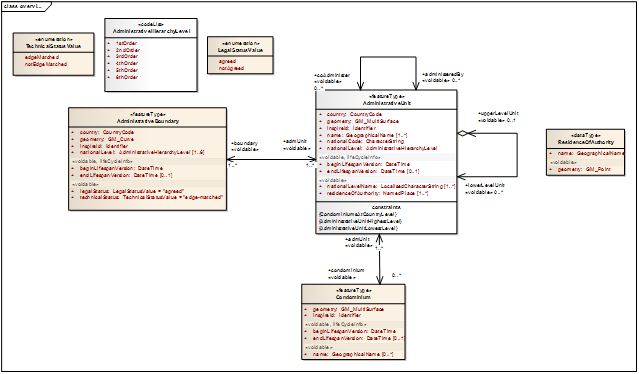
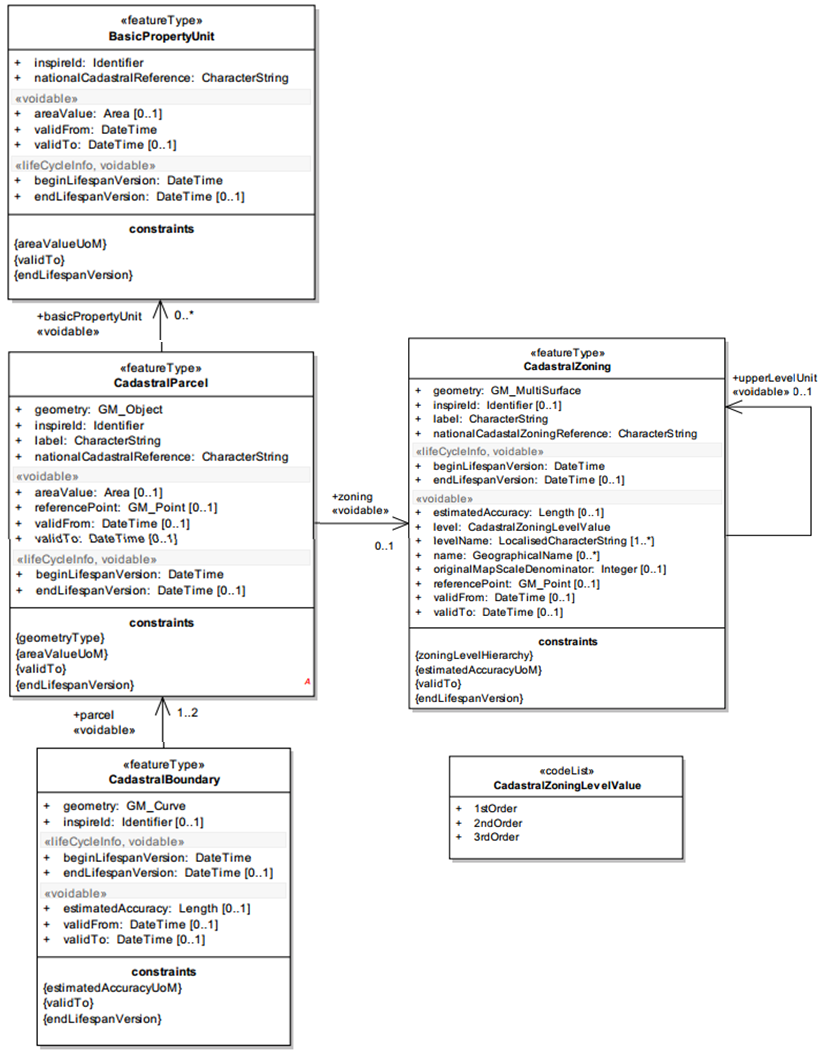
CP - Application schema
This slide shows you the UML diagram of the CP application schema which is not complicated. We can distinguish 4 classes that are related to each other. Centrally we have the cadastral parcel which is part of a cadastral zone (the class on the right). The cadastral parcel is defined by its boundaries (the class at the bottom) and on top of the slide we have the basic property unit which is optional for countries where national cadastral reference is given to one or a group of parcel(s) defined by unique ownership and homogeneous real property rights.
CP – Feature types
CadastralParcel (mandatory)
CadastralZoning (auxiliary)
CadastralBoundary (auxiliary)
BasicPropertyUnit (auxiliary)
Notes for slide 49
Here we see a list of the four classes as feature types (i.e. spatial identifiable objects). And we can see that there is only 1 feature type mandatory (cadastral parcel) all the rest is auxiliary (mandatory in specific conditions) but the core profile is actually limited to the Cadastral parcel feature type.
CP - Requirements & Recommendations
On this slide you see an IR requirement (remember the style, red and the double border), and some recommendations that were defined for the CP theme.
CP - Requirements & Recommendations
This slide illustrates that the DS is a technical guidance for data providers. In this case it shows how to deal with lifecycle issues of CPs. It gives some examples from reality where CP can change in time and the way these types of changes should be treated: either as a new parcel with a new identifier or just as a new version of the parcel with the same identifier, which than implements that the old version becomes retired.
CP - Requirements & Recommendations
Here we have an important recommendation that says that INSPIRE cadastral parcels should only be published when the parcels are officially published in the national register. So for work in progress it is not necessary to make it available through INSPIRE unless it is published in the National register i.e. when it is officially validated.
CP - Geometry
0-, 1-,2-,2,5 dimensional geometries
These recommendations on geometry we have seen already, so polygons are recommended but by looking at the model we have seen that 1-dimensional features (boundaries) are also acceptable under certain circumstances.
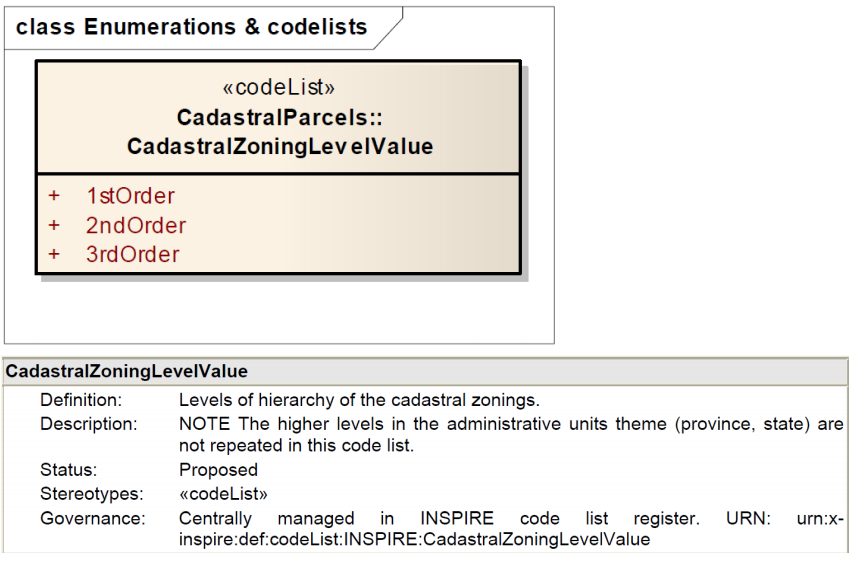
CP - Enumerations/codelists
Here you have an example of a codelist that provides the values that should be used to indicate the levels of aggregation (hierarchy) of cadastral zones.
Land Administration Domain Model
Major packages of the data model
Reference list
ISO/TC 211 Geographic information/Geomatics. (2007). ISO 19131:2007. ISO. Retrieved October 19, 2020, from https://www.iso.org/cms/render/live/en/sites/isoorg/contents/data/standard/03/67/36760.html Brodeur, J., & Badard, T. (2008). Modeling with ISO 191xx Standards. In S. Shekhar & H. Xiong (Eds.), Encyclopedia of GIS (pp. 705–716). Springer US. https://doi.org/10.1007/978-0-387-35973-1_811 ISO, I. (2015). 19109: 2015 Geographic information-Rules for application schema. International Organisation for Standardization.